Ceph 读写流程:file_to_extents 过程分析
本文介绍 Ceph 中条带化的相关概念并对 Striper::file_to_extents 的流程进行了分析和总结。
在 Client::_write 中客户端通过 filer->write_trunc 对文件进行写入,write_trunc 其中分为两步:
- 通过
Striper::file_to_extents对请求进行拆分,也就是将对文件的读写请求转换为对对象的读写请求 - 通过
objecter->sg_write_trunc把数据写到 object 中
本文主要对其中的第一步,也就是 Striper::file_to_extents 的过程进行分析。
Ceph 中的 Stripping
在正式开始先简单介绍一下 Ceph 中条带化(Stripping)读写的相关概念:
为什么要使用 Stripping
最主要的原因就是由于单个存储设备存在吞吐量限制,例如一块机械硬盘的写入能力最大也不过 200MB/s, 在与内存、固态缓存甚至是万兆网络的吞吐量对比下无疑就是整个系统中最大的短板,那么条带化就是用来解决存储设备性能瓶颈,提高存储系统吞吐量的东西。
那么什么是条带化,说的准确一点就是把信息的连续部分存储在多个存储设备上,说人话就是把一个文件切成多份放在不同的磁盘上,每次对文件中一段内容的读写会同时发给多个盘,这样的话我们实际的写入速度就变成了多个磁盘的写入速度总和。
Ceph 中的条带化的概念大致和其他存储没有区别,只不过在 Ceph 中所有的存储最后都会落到 object 也就是对象上,而对象的存储是没有条带化的,因此文件的条带化实际上是在客户端上进行的,也就是我们本文的主要内容 file_to_extents 的过程
以下图为例,对文件数据的写入首先会在 ObjectSet1 的 Object0 的 stripe unit0 中进行, 当第一个条带被写满之后,后续的写会移动到 Object1 的 stripe unit1 上进行,直到 Object3 的 stripe unit3 被写满之后 Ceph 会根据 ObjectSet 中可容纳的对象数量判断是否写满,并将后续的写转回到 Object0 上的 stripe unit4 中进行。而这个过程在一次包含比较多数据的写中当然是可以并行执行的,只要我们提前计算好写入涉及的 objects 即可。
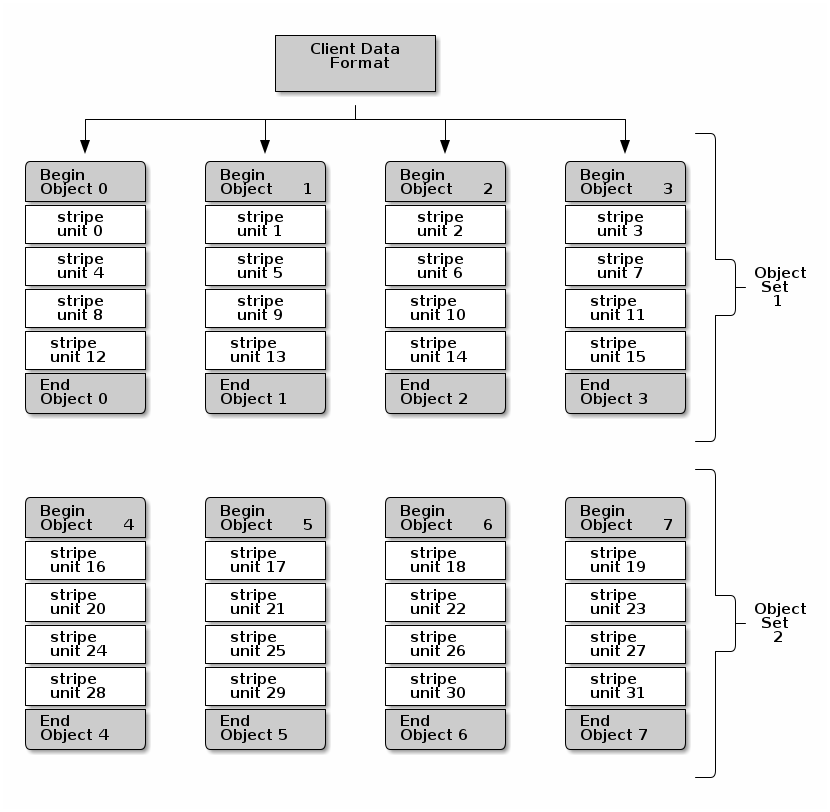
file_to_extents 流程
概念理解以后我们就正式来看 file_to_extents 的过程,首先看一下在 Filer::write_trunc 是如何调用 file_to_extents 的:
1 | // osdc/Filer.cc |
这里传入的 ino offset 和 len 比较好理解,就是我们要写入的文件的 Inode 号,然后从哪里开始写,要写多长,注意这里因为只是算映射所以是不需要传 bl 也就是真正要写入的数据的。
接着 truncate_size 和 truncate 写有关所以我们先不过多关心,那么 layout 就是用来辅助我们切分请求的,而 extents 就是我们稍后真正要写入的 ObjectExtent 集合了,定义如下:
1 | std::vector<ObjectExtent> extents; |
ObjectExtent 就是我们对于某一个 object 要写入的条带的集合,定义如下:
1 | class ObjectExtent |
其中我们通过 oid 和 objectno 找到一个 object,而 oid 就是文件的 inode 号。
offset 和 length 则是要写入 object 的这段数据在 object 中的偏移和长度(从上图我们可以看到一段连续的数据按条带写到 object 中实际也是连续的)
buffer_extents 则是要写入 object 的数据在 buffer 中的偏移和长度,这里的 buffer 指的是实际的数据,比如一个刚好写满上图 5 个条带的数据必然会横跨三个条带,这时我们就需要在 buffer_extents 中记录下 buffer 中要写入 object 的两段数据的偏移和各自的长度。
理解了上述部分以后,我们就实际看一下 file_to_extents 是如何填充 extents 的:
1 | static void file_to_extents(CephContext *cct, inodeno_t ino, |
第一步就是将 ino 写入 buf 然后进入第二个版本的重载:
1 | void Striper::file_to_extents(CephContext *cct, const char *object_format, |
这里可以看到又多了一个 LightweightObjectExtents,实际上这个和 ObjectExtent 的区别就是没有 object_locator_t oloc,进入第三个版本的重载:
1 | void Striper::file_to_extents( |
首先读一下 layout,object_size 和 stripe_unit 我们刚刚都提到了,stripe_count 实际就是每个 ObjectSet 中包含的 object 数量:
1 | // void Striper::file_to_extents |
如果 stripe_count 为 1 的话切条带就没有意义了,因此我们直接让一个 object 中只包含一个条带即可:
1 | if (stripe_count == 1) { |
接下来就进入到切分的过程,这个过程稍微有点长,其中涉及的变量如下:
Striper::file_to_extents
1 | uint64_t stripes_per_object = object_size / su; |
插入 object_extents 的过程分两种情况,其中 if 分支是插入一个新 LightweightObjectExtent,else 分支则是写满一组条带之后更新 LightweightObjectExtent 的过程
首先看 if 分支,满足下列条件其中之一的进入此分支:
object_extents为空- 当前
object_extent不存在于object_extents中 - 写入的数据在
object中不是连续的
进入分支以后直接插入一个 LightweightObjectExtent 到 object_extents 即可:
1 | striper::LightweightObjectExtent* ex = nullptr; |
接着 else 分支则是对 LightweightObjectExtent 中的 length 进行更新:
1 | } else { |
以上两种情况我们都需要对 buffer_extents 进行更新,插入这段数据在 buffer 中的偏移和长度,并更新下一轮我们待切分的数据长度 left 和已经切分的偏移位置 cur:
1 | ex->buffer_extents.emplace_back(cur - offset + buffer_offset, x_len); |
全部切分完成并加入 object_extents 之后我们回到第二个版本的 Striper::file_to_extents 中,在这里遍历 lightweight_object_extents 并填入 extents,这里基本上就是原样填充,只多了一步就是算了一下 oloc:
将 LightweightObjectExtent 转换为 ObjectExtent
1 | // convert lightweight object extents to heavyweight version |
以上就是关于 Ceph 条带化的介绍和 Striper::file_to_extents 的全部过程。